AI, ML, DL - Decoding the Alphabet Soup of Artificial Intelligence
Have you ever wondered how Netflix knows exactly what to recommend to you when you open the application, or how Siri, Alexa, or Google can understand what you’re saying and talk back to you? Each of these applications is powered by a concept that has now become ubiquitous - Artificial Intelligence (AI).
Humans have been trying to mimic the world around them since time immemorial. Observing fish in the sea inspired us to create boats and submarines equipped with sonar technology, aiding navigation through the oceans. We saw birds flying in the sky, and we built airplanes to do just that. So, you see, humans are pretty damn intelligent. It’s no wonder we want our latest invention, the computer, which up until now had mostly been good at fast processing and complex computation, to simulate human intelligence. To talk the way we talk, understand the way we understand, and see the world the way we see it.
Thus, in crux, Artificial Intelligence is a technique that enables computers to emulate human intelligence. When machines demonstrate the ability to perform tasks typically associated with human cognitive functions, we attribute these capabilities to AI. IBM states that AI, in its simplest form, is a field that combines computer science and robust datasets to enable problem-solving.
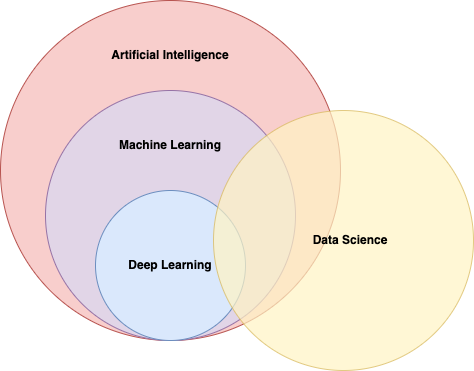
But what exactly distinguishes Machine Learning (ML) from AI, and where does Deep Learning (DL) fit into the picture? As depicted in the above figure, AI acts as a superset, encompassing various technologies and methodologies to simulate human-like intelligence. ML is one of its subsets, and further, DL is nested within ML. Each layer builds upon the other, leading to increasingly sophisticated capabilities. In this interconnected landscape, Data Science emerges as a critical enabler, traversing the domains of AI, ML, and DL.
Machine learning is a subset of AI that enables machines to enhance task performance through experience. ML focuses on algorithms and techniques that allow machines to learn from data and iteratively improve their performance over time. For instance, consider the task of email classification, distinguishing between spam and legitimate emails. In this scenario, an ML model analyzes a dataset containing labeled examples of emails and learns patterns to classify emails as spam or non-spam. The main aim of ML is for the model to perform well on new, unseen data. Thus, by training on this labeled dataset, the model gains the ability to classify new, unseen emails accurately. Other real-world applications of ML include stock market predictions, tumor detection,and credit card fraud detection. However, when confronted with tasks of increased complexity and intricacy, traditional machine-learning approaches may reach their limits and we need to use deep learning.
Deep learning, with its foundation in neural networks, revolutionizes the field of machine learning. It empowers systems to extract intricate patterns and representations from vast amounts of data, enabling unprecedented levels of understanding and prediction. The “deep” in deep learning refers to the depth of neural networks, with architectures comprising multiple layers, often more than three. The deep neural networks attempt to identify the patterns the way the human brain does.
But what exactly is a neural network, and how does it relate to deep learning?
In the human body, neural networks are represented by the complex interconnected network of neurons in the brain and nervous system. These neural networks play a fundamental role in processing and transmitting information throughout the body.
Inspired by the biological neural networks, artificial neural networks are designed to mimic this structure. The design is such that each layer processes information and passes it on to the next, allowing the network to progressively learn and abstract complex features from the input data. This process, known as “training”, involves adjusting the connections between nodes based on observed patterns in the data. An important thing to note here is that deep learning typically requires a lot more data than traditional ML algorithms for effective training.
Text to speech, speech to text, image classification, sentiment analysis, machine translation are all applications of deep learning. You may notice that the input in the above applications is either images or speech/text. This observation gives rise to the two main sub-domains of deep learning - computer vision (CV) and natural language processing (NLP).
When the input data consists of images or videos, the domain responsible for processing it is computer vision. On the other hand, when the input data comprises speech or text, NLP is the domain tasked with handling it.
In computer vision, the models process images and videos to help the computer perceive and interpret the world similarly to humans. Tasks such as differentiating between different objects in an image, identifying different types of plant species, and action recognition in videos, are all examples of computer vision. On the other hand, natural language processing focuses on the processing and understanding of human language. This includes tasks such as text summarization, sentiment analysis, language translation, and more. Both computer vision and natural language processing rely on deep neural networks and massive datasets to learn complex patterns and representations from the data.
But where does data science fit into all of this?
Well, none of these systems can function effectively without data. It’s often said that data is the new oil, and rightfully so. Data science serves as the backbone of these fields, encompassing the methodologies and practices involved in collecting, processing, analyzing, and interpreting large volumes of data to extract meaningful insights. Data science plays a crucial role in every stage of the development lifecyle of AI, ML, and DL systems. From data collection and preprocessing to model training and evaluation, data science techniques ensure the quality, relevance, and reliability of the data used to train and deploy intelligent systems.
As we conclude our introduction to different terminologies used in the AI ecosystem, it’s important to acknowledge the several challenges and limitations associated with these technologies. From data biases to ethical concerns and the demand for computational resources, AI scientists and ML engineers face a number of considerations when building such intelligent systems.
We have only scratched the surface of the vast landscape of AI, ML, DL and data science, but I hope this introduction has given you some insights and clarity into these concepts. So, buckle up and get ready for an exhilarating journey through the realms of artificial intelligence and machine learning!