Machine Learning - Lifecycle and Key Types
Let’s dive into one of the quintessential examples in machine learning: building a spam email classifier. How do we take raw data and transform it into a predictive model that can accurately differentiate between spam and legitimate emails? The answer lies in following a systematic approach known as the Machine Learning lifecycle. This lifecycle isn’t just about training models; it encompasses understanding the data, crafting meaningful features, and continuously refining the model’s performance over time.
Understanding the end-to-end process of the Machine Learning lifecycle is crucial before delving into the intricacies of model development.
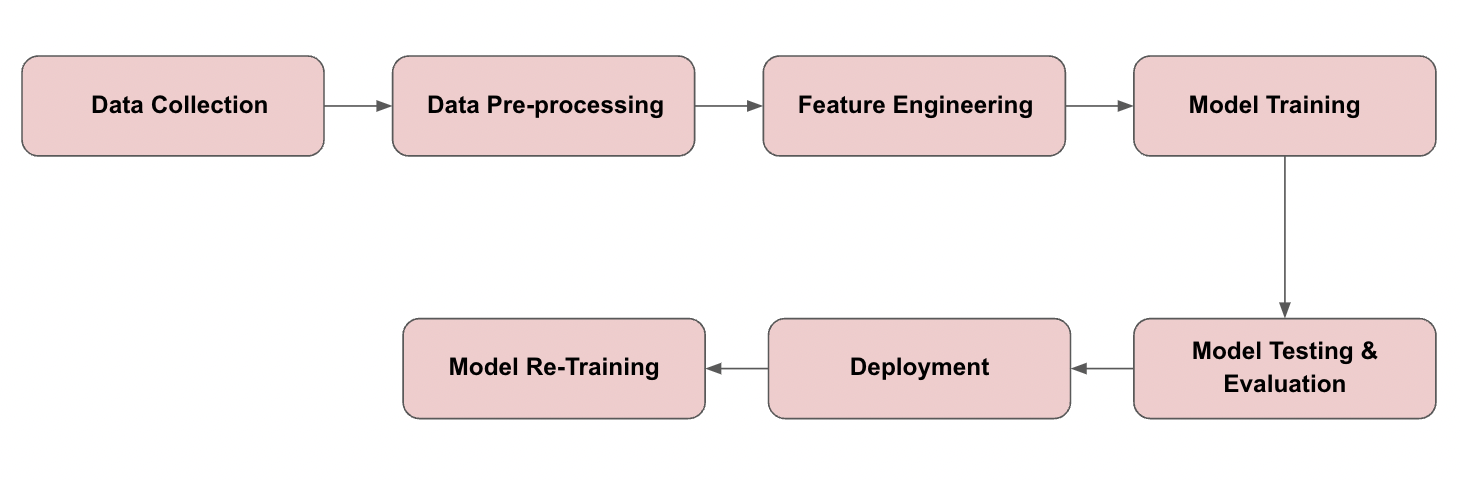
Here’s a breakdown of the key stages:
- Data Collection - this initial stage involves gathering data relevant to our application from various sources such as email servers or labeled datasets containing spam and non-spam emails.
- Data Pre-processing - identifying relevant data and converting it into a model-friendly format by handling missing values, removing duplicates, and ensuring data consistency.
- Feature Engineering - we create new features or transform existing ones to extract meaningful information that can improve the model’s predictive power.
- Model Training - train your machine learning model using the prepared dataset and engineered features.
- Model Testing & Evaluation - after training, it’s crucial to evaluate the model’s performance using a separate test dataset. Metrics like accuracy, precision, recall, and F1 score help assess the model’s effectiveness and how well the model generalizes to new data.
- Deployment - once you have a well-performing model, you deploy it into production for real-world use.
- Model Re-Training - periodically re-training the model as new data becomes available or the data landscape changes to maintain accuracy and relevance.
By following this iterative process, machine learning practitioners enhance their models’ accuracy and effectiveness in dynamic environments. This workflow applies to not just the email spam filtering example, but also to various traditional machine learning tasks. In addition to the outlined stages of the Machine Learning lifecycle, it’s important to highlight that in a business setting, the first step often involves defining the business problem or formulating a clear problem statement. Between the model training step and testing & evaluation step, we often experiment with a variety of models and choose the model that performs best on validation or test data.
In our previous blog, we defined ML as a subset of AI that enables machines to enhance task performance through experience. Broadly machine learning can be further divided into Supervised Learning, Unsupervised Learning and Reinforcement learning.
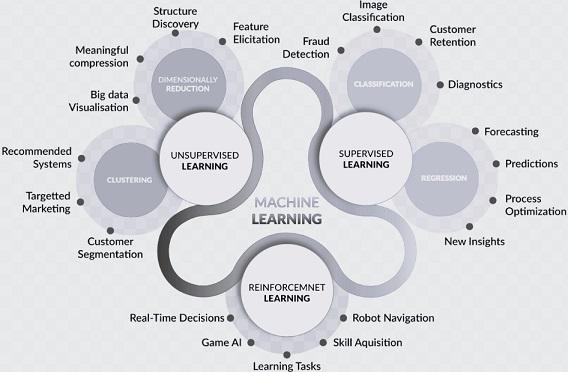
Fig reference: GeeksforGeeks
Supervised Learning
Supervised Learning, as the name suggests, involves the presence of labeled data. In this scenario, the model is provided with input-output pairs, where the input data is labeled with the corresponding correct output. The model learns from this labeled data to make predictions or classify new, unseen data accurately. For instance, in a spam email classifier, the model is trained on a dataset where each email is labeled as spam or not spam, allowing it to learn the patterns associated with each class.
As we can see in the figure above, supervised learning is further divided into classification and regression. Both classification and regression take a set of training instances and learn a mapping to a target value. The target value can be discrete or continuous. For classification, the target value is discrete. Classification algorithms can be binary, where the output is one of two possible classes, or multiclass, where the output can be one of several classes. For regression, the target value is continuous, such as stock prices, and housing prices.
Many supervised learning methods have flavours for both classification and regression.
Unsupervised Learning
On the other hand, Unsupervised Learning deals with unlabeled data, meaning there are no predefined output labels. Unsupervised learning algorithms can uncover hidden relationships, clusters, or anomalies in the data that may not be apparent to human observers. In tumor detection using unsupervised learning, algorithms analyze medical images to identify patterns without labeled data. For example, clustering algorithms can group similar images together based on features like shape and texture, helping doctors spot potential tumor classifications efficiently. Another place where unsupervised learning is heavily used is in recommendation systems where algorithms analyze user behavior and item attributes to generate personalized recommendations.
The two main types of unsupervised learning are clustering and dimensionality reduction. Clustering groups similar data points together based on their characteristics. Dimensionality reduction algorithms reduce the number of input variables in a dataset while preserving as much of the original information as possible. This is mainly done when we want to reduce the complexity of the dataset and help us better visualise the data.
Reinforcement Learning
Reinforcement Learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties based on its actions, guiding it to learn the optimal behavior over time. It’s like teaching a dog new tricks through a series of rewards and corrections until it learns the desired behavior.
We also have semi-supervised learning (SSL) which has not been shown in this diagram but is extensively used in real-life applications. SSL is used when only part of the data is labelled. Here, you train an initial model on a few labeled samples and then iteratively apply it to the greater number of unlabeled data. SSL works for a variety of problems from classification and regression to clustering and association.